Big Data
Oracle Big Data 可帮助数据专业人员管理、编目和处理原始数据。Oracle 提供对象存储和基于 Hadoop 的数据湖来实现持久化,提供 Spark 进行数据处理,并通过 Oracle Cloud SQL 或客户自行选择的分析工具进行分析。

利用数据湖整合所有数据
-
完备的集成式解决方案
部署一个完备的集成式解决方案,包括数据管理、数据集成和数据科学,帮助分析团队实现企业数据的最大价值。客户可通过批处理、流处理和实时处理方式提取数据,并根据需要将其存储在数据仓库或数据湖中。然后,团队对数据进行编目和应用治理,以便将其用于分析、可视化和机器学习模型。IT 团队在数据仓库和数据湖中采用一致的安全性策略。
-
易于管理和操作
利用可通过 API 访问的全托管式无服务器 Apache Spark 集群提高开发人员的工作效率。自动供应、保护和关闭每个集群,以减少开发人员的工作量。客户可以部署任意规模或款型的全托管式 Hadoop 集群,然后一键添加安全性和高可用性。
-
可部署在 Oracle Cloud 数据中心或客户数据中心
根据需要部署 Oracle 大数据服务,满足客户数据驻留和延迟要求。对于大数据服务以及所有其他 Oracle Cloud Infrastructure 服务,客户都可以在 Oracle Public Cloud 中使用,或者将其作为 Oracle Dedicated Region Cloud@Customer 环境的一部分部署在客户数据中心。
Oracle 大数据产品
-
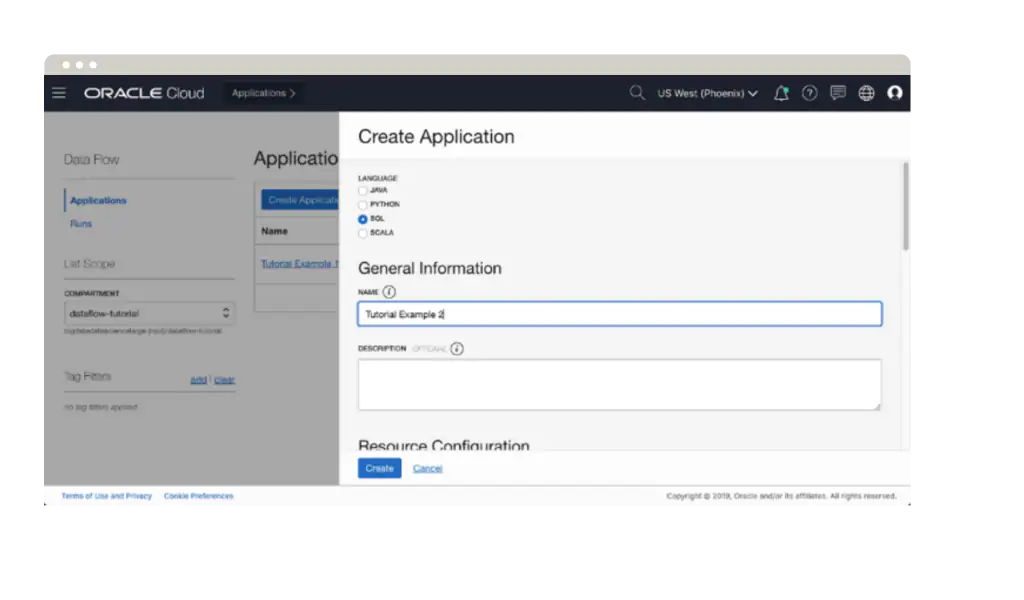
Oracle Cloud Infrastructure Data Flow
Oracle Cloud Infrastructure Data Flow 是一个全托管式的 Apache Spark 服务,无需客户 IT 团队部署或管理任何基础设施。使用 OCI Data Flow,开发人员可以专注于开发应用,不用在运营上分心,从而加快应用交付。
-
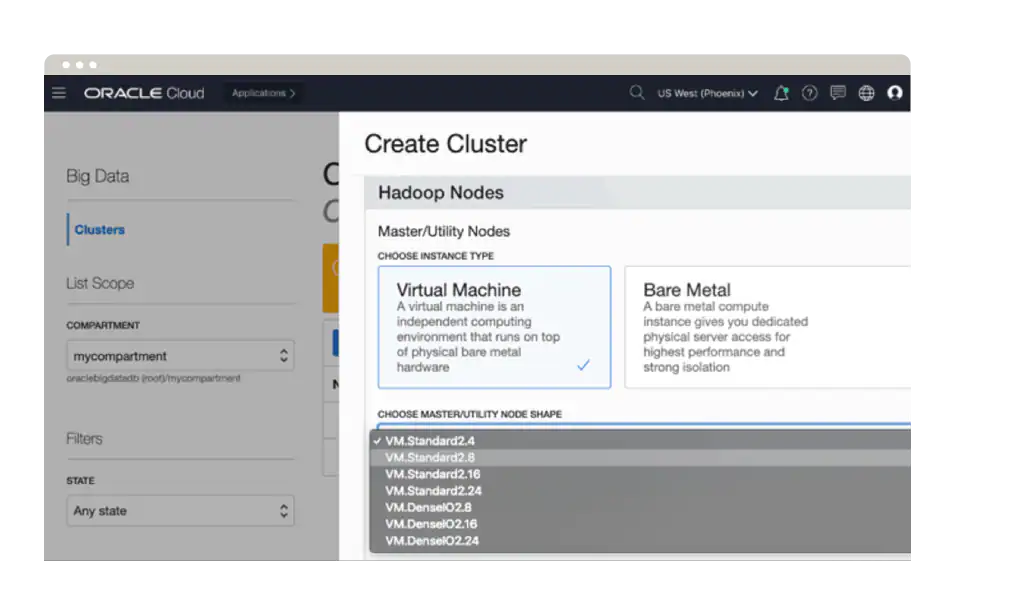
Oracle Big Data Service
Oracle Big Data Service 是一个基于 Hadoop 的数据湖,可用于存储和分析大量原始客户数据。作为一项托管服务,Oracle Big Data Service 随带一个全面集成的体系,其中的开源工具和 Oracle 增值工具可有效简化 IT 运营。借助 Oracle Big Data Service,企业可以更加轻松地管理整个组织中的数据并从中发掘价值。
-
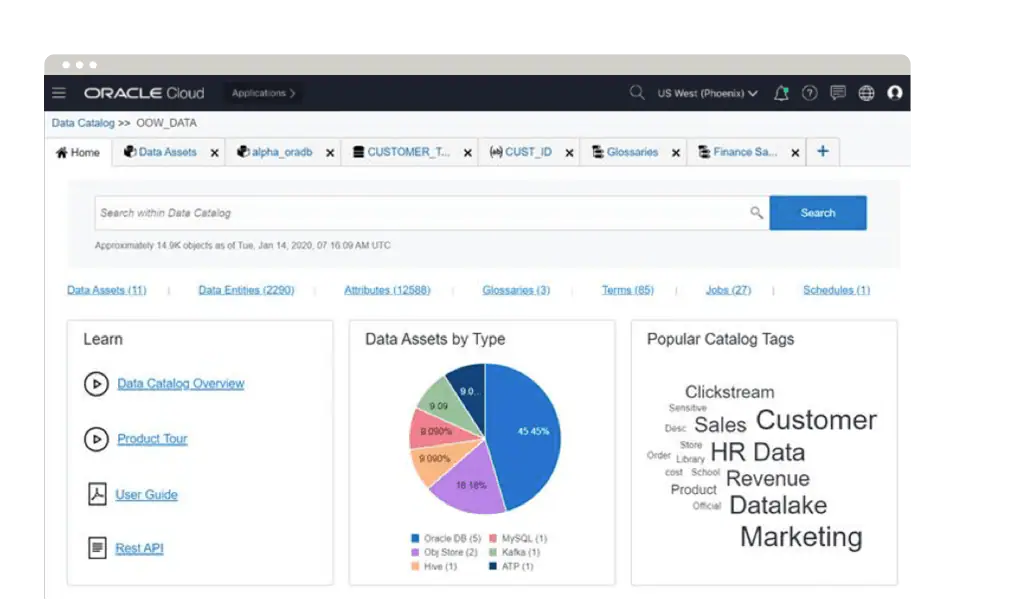
Oracle Cloud Infrastructure Data Catalog
Oracle Cloud Infrastructure Data Catalog 有助于企业的数据专业人员使用整个企业的数据资产清单来搜索、探究和治理数据。它能自动在企业的数据存储中收获元数据,为数据湖提供通用的元存储。对于位于 Oracle Cloud Infrastructure 及其他位置的数据资产,Data Catalog 简化了业务术语表和精选信息的定义,使数据使用者可以轻松找到所需数据。